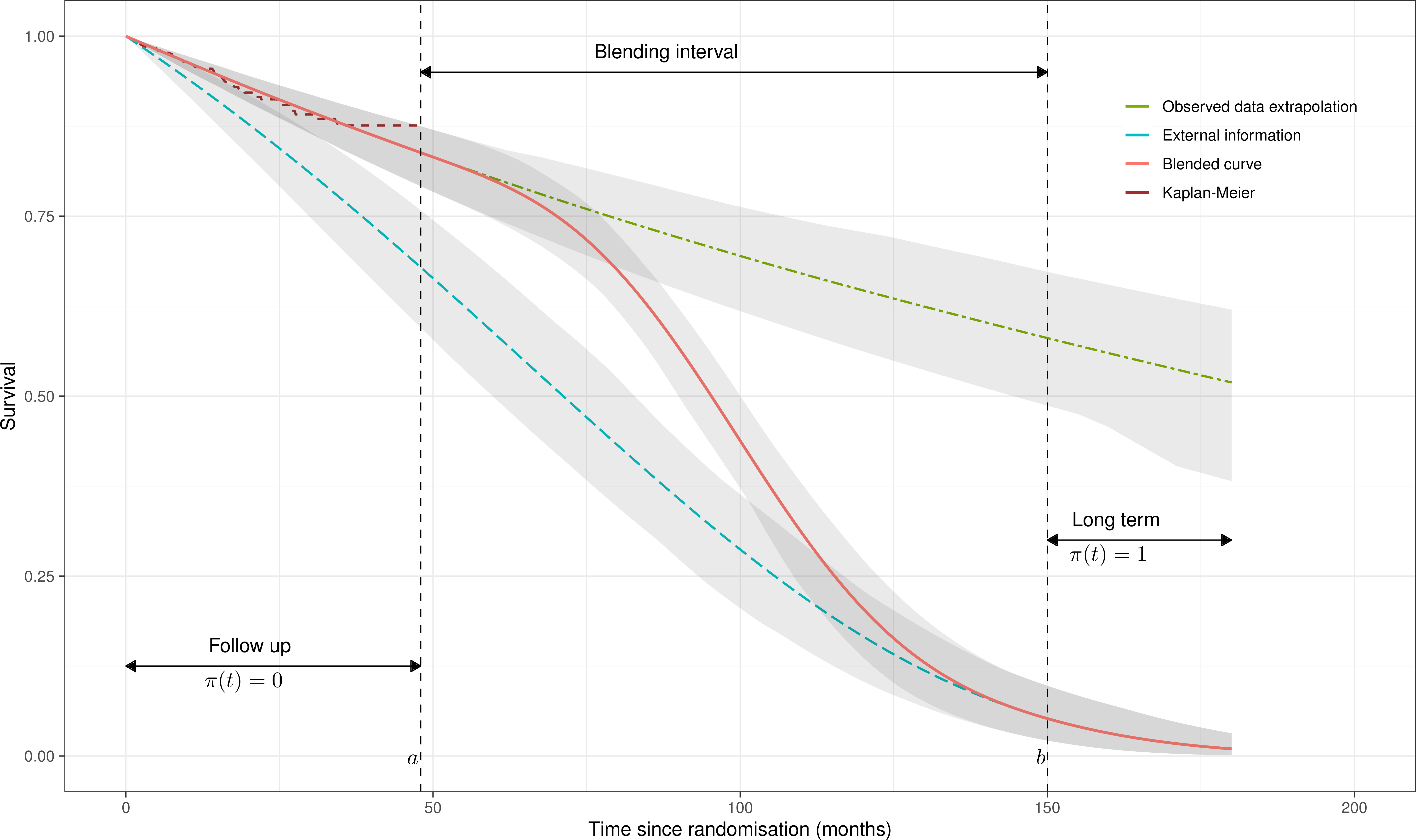
blendR implements the method proposed by Che, Green, and Baio (2022), which can be used when we need to extrapolate a survival curve for which data are available on a most likely short-term follow up and subject to large censoring.
The economic model must consider the long-term performance of a given intervention and the point of the “blending” idea is to recognise that, often, the observed data are simply just not enough to produce a sensible estimate of the survival both over the observed time interval and in the long run. To make up for this inconsistency in the available data, blending assumes that the overall survival curve is described using two processes
Driven exclusively by the observed data
This is similar to a “standard” HTA analysis, based on an estimated survival curve \(S_{obs}(t\mid\boldsymbol\theta_{obs})\). The main objective is to produce the best fit possible to the observed information, but unlike in a “standard” modelling exercise, where the issue of overfitting is potentially critical, achieving a very close approximation to the observed dynamics has much less important implications in the case of blending.
“External” process
Used to derive a separate survival curve, \(S_{ext}(t\mid\boldsymbol\theta_{ext})\) to describe the long-term estimate for the survival probabilities. One could use “hard” evidence (eg RWE/registries/cohort studies/etc), or purely subjective knwoledge elicited from experts (or both!).
Blending occurs by combining the two processes to obtain a single survival curve \[S_{ble}(t\mid \boldsymbol\theta) = S_{obs}(t\mid\boldsymbol\theta_{obs})^{1-\pi(\alpha,\beta; a,b)} \times S_{ext}(t\mid\boldsymbol\theta_{ext})^{\pi(\alpha,\beta; a,b)}\] where:
\(\boldsymbol \theta = \{\boldsymbol \theta_{obs}, \boldsymbol \theta_{ext}, \alpha, \beta, a, b\}\) is the vector of model parameters;
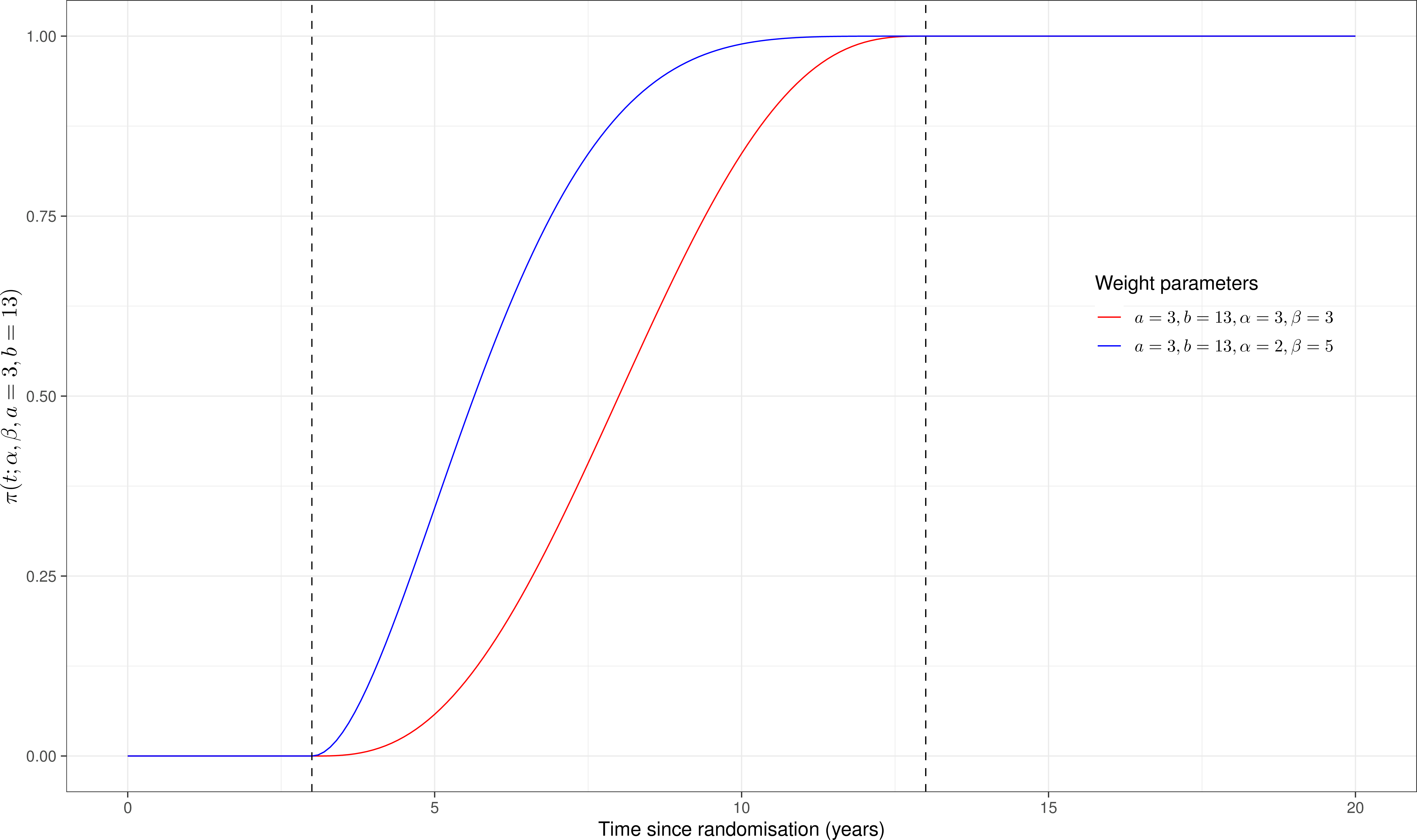
\(\displaystyle \pi(t;\alpha,\beta,a,b) = \Pr\left(T\leq \frac{t-a}{b-a}\mid \alpha, \beta\right) = F_{\text{Beta}}\left (\frac{t-a}{b-a}\mid \alpha, \beta \right)\) is a weight function controlling the extent to which \(S_{obs}(\cdot)\) and \(S_{ext}(\cdot)\) are blended together
\(t \in [0,T^*]\), is the interval of times over which we want to perform our evaluation.
Basically, we want to use the best-fit survival curve in the portion of the time interval where we have information and then increasingly quickly abandon the extrapolation from this model, which is likely to produce unrealistic results, to give more and more weight to some “external” curve, in which we are reasonably comfortable in terms of the long term predictions for the survival probabilities.
The blending (mixing) process is explicitly modulated by the weight function — we can fiddle with the values \(\alpha,\beta,a,b\) to perform sensitivity analysis, effectively removing the pressure on a single model to deliver the best and most reasonable results on the whole range of times that we are interested in. Different choices of the parameters imply that the blending process happen more or less quickly.
The process remains potentially subject to uncertainty and arbitrary choices (which is by and large unavoidable in many relevant cases in HTA!), but this happens in a way that can be discussed more transparently — and crucially forces the user to make the most of external knowledge to complement the limited information available from the observed data.
Installation and use
You can install the development version of blendR from itsGitHub repository by typing on your R terminal the following command.
# First install `remotes` (only needed once!)install.packages("remotes")# Then install `blendR` from GitHubremotes::install_github("StatisticsHealthEconomics/blendR")
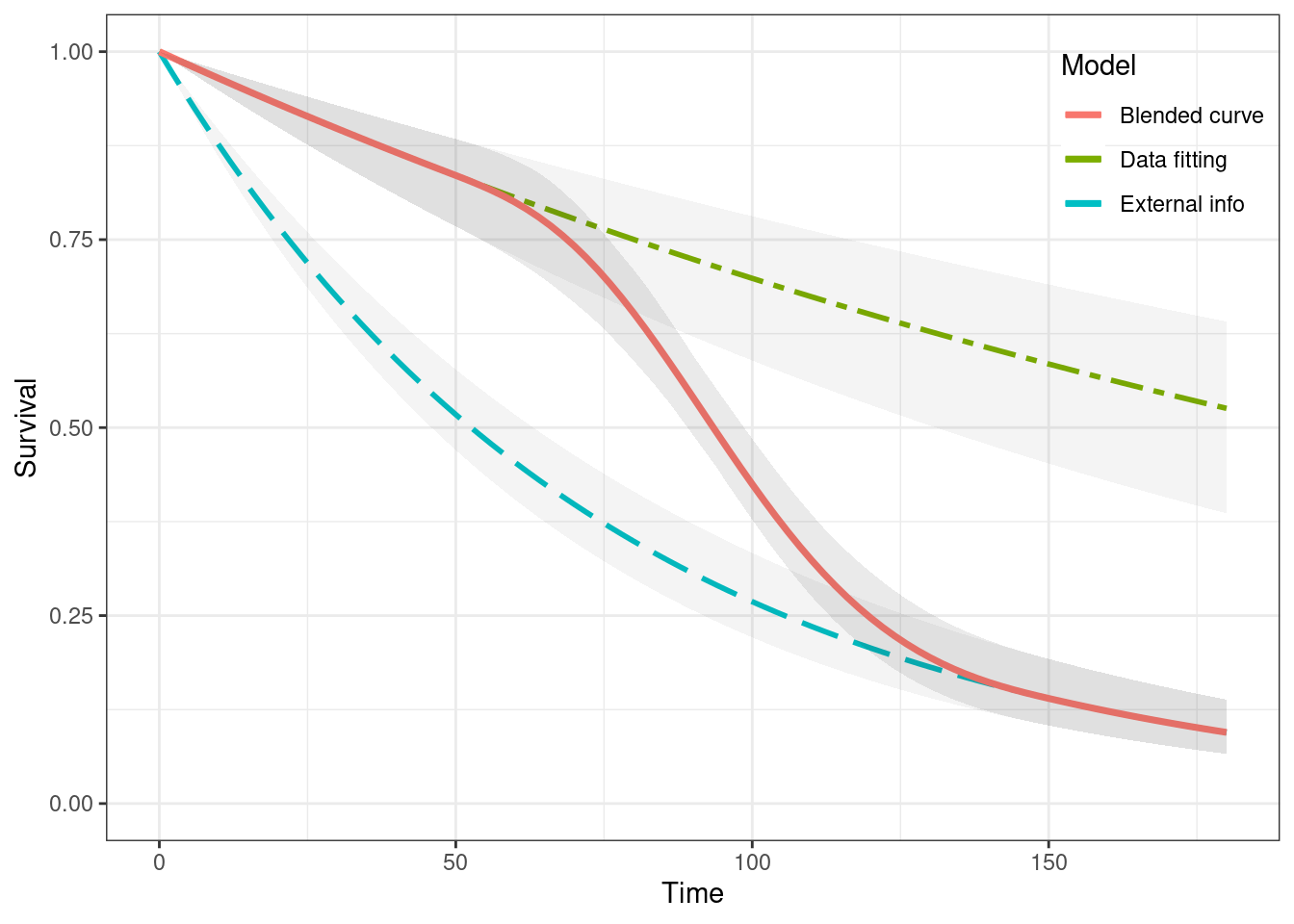
A very basic example is provided below, using the TA174_FCR data set contained in the blendR package. We fit exponential distribution survival models with no covariates using the fit.models() function from the survHE package — in this case we choose a Bayesian version of the model, based on HMC. The external or long-term data are obtained from an heuristic approach to simulating data consistent with user-defined constraints — see Che, Green, and Baio (2022) for more details. The results are then blended into a single survival curve using the blendsurv() function.
library(blendR)library(survHE)## trial datadata("TA174_FCR", package ="blendR")## elicitation for long-term survivaldata_sim <-ext_surv_sim(t_info =144,S_info =0.05,T_max =180)## fit to the observed data obs_Surv <-fit.models(formula =Surv(death_t, death) ~1,data = dat_FCR,distr ="exponential",method ="hmc")## estimate the long-term survival ext_Surv <-fit.models(formula =Surv(time, event) ~1,data = data_sim,distr ="exponential",method ="hmc")## defines the blending interval and its parameters blend_interv <-list(min =48, max =150)beta_params <-list(alpha =3, beta =3)## uses `blendR` to produce the blended curveble_Surv <-blendsurv(obs_Surv, ext_Surv, blend_interv, beta_params)## and then plots the resultsplot(ble_Surv)
Last updated: 18 September 2025
Relevant publications
Che, Z, N Green, and G Baio. 2022. “Blended Survival Curves: A New Approach to Extrapolation for Time-to-Event Outcomes From Clinical Trials in Health Technology Assessment.”Medical Decision Making, September. https://doi.org/10.1177/0272989X221134545.