Post mortem

This is again a guest post, mainly written by Roberto, which I only slightly edited (and if significantly so, I am making it clear by adding text in italics and in square brackets, like [this]). By the way, the pic on the left shows my favourite pathologist examining a post-mortem.
A day after the bull-fight is over and done with (at least until the next election, which may be sooner than one would expect), we have to do some analysis as to what went right, and what failed, as it regards to our model. First let’s look at the results:

Right off the bat, we can say a few things: firstly, the model captures the correct order of the parties, and hence the results of this election, with impressive certainty. A study of our simulations suggest that if this election was run 8000 times, we would get the correct ranking of parties according to seats 90% of the time, with the remaining 10% having Ciudadanos ahead of Podemos, and the other parties still in their correct place. The model predicts the correct ranking of parties according to votes 100% of the time.
This is an interesting point because towards the end of the campaign it looked as if Ciudadanos could overtake Podemos, but came way short on election day. It is also interesting to see that the Popular Party performed better than expected, and one could think that, due to the ideological similarities, when it came to election day some Ciudadanos aficionados opted to vote for the PP, anticipating that they were better positioned to govern.
This explanation only holds in part, since we would have to understand why the same reasoning didn’t apply to Podemos voters. However a key could lie in the under-performance of the “Other” parties, which due to their regional anti-central-government nature, and their mostly left-leaning ideology, may have been an easy prey for the Podemos tide.
Whatever the true mechanism, this highlights the main problem with our model, which is that we didn’t model the substitution effect among parties. For future references, I believe these results point to two important variables which can forecast whether a party ends up “swallowing” votes from another: similarity of ideology and probability of achieving significantly (in political terms) more seats that the other party.
When we look at the number of seats won, the model has a Root Mean Squared Error (RMSE) of just below 10 seats, suggesting that the true number of seats gained by a party lies 10 seats away from my forecast on average. 10 seats represents just shy of 3% of the total seats, so when put in context, this is not a huge margin of error, and it is clearly low enough to allow us to make relevant and useful inference as it regards the results, 5 days before the election. However we could have probably improved on this, perhaps by trying to model regional races separately, which would have enabled us to witness the “finalists” of each race, perhaps allowing us to reduce the overall variability.
As it regards to vote shares, our RMSE is around 2%, suggesting our vote share estimate for each party is around 2% away from its actual result. This is better than the seats estimate, perhaps due to the larger number of polls at our disposal, as well as the lower variability due to the absence of sources of external variability such as the electoral law.
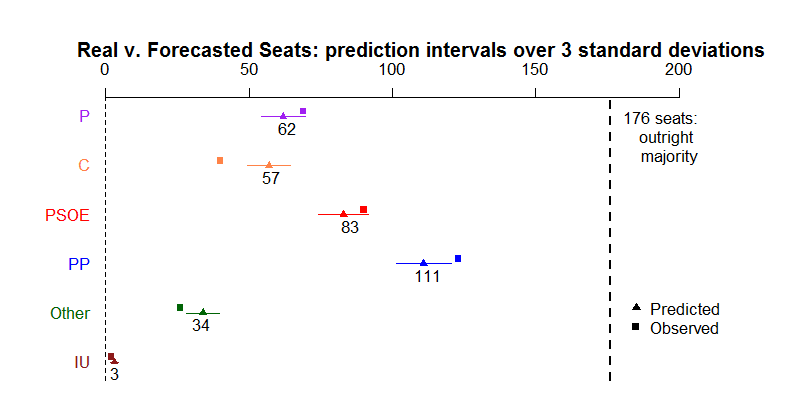
When we plot our prediction intervals for seats against the actual results and we stretch the prediction interval slightly to include 3 standard deviations (hence including even rare outcomes under our model), it becomes evident that this was indeed somewhat of a special election. Almost all of the results are either at the border of our prediction, or have jumped past it just slightly, with the only exception being Ciudadanos. This suggests that, beyond the Ciudadanos problem, this election was an extreme case under our model, meaning that either our model could have been better, or we were just very unlucky. I tend to believe the former.
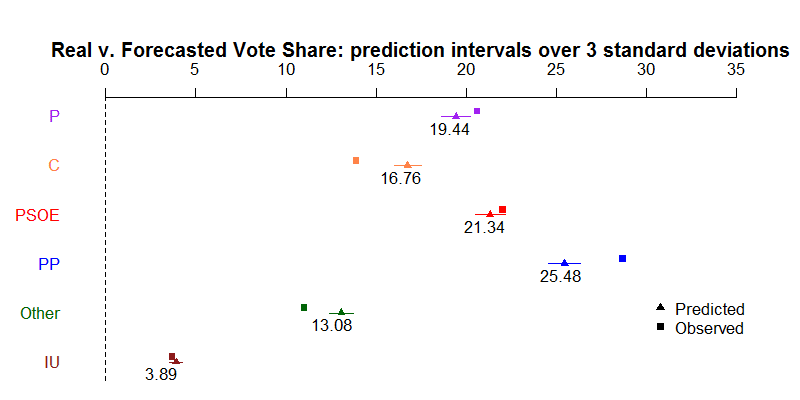
Our vote share results also hold some interesting clues. Although our point estimates here do better on average than for the seats, we pay the price to some over-confidence in our estimates. Our prediction intervals just aren’t large enough. This could be for several reasons, including perhaps too high a precision parameter over our long-run estimates. Moreover, polls may have been consistently “wrong”, leading our dynamic Bayesian framework to converge around values which, sadly, were untrue. We should look into mitigating this effect through more thorough weighing of the polls. [I think this is a very interesting point and similar to what we’ve seen with the UK general elections a few months back, where the polls were consistently predicting a hung parliament and suggesting a positive outcome for the Labour Party, which (perhaps? I don’t even know what to think about it anymore…) sadly never materialised. May be the question here is more subtle and we should try and investigate more formal ways of telling the model to take the polls with a healthy pinch of salt…]
Other forecasters attempted the trial, with similar accuracy as our own effort, but using different methodologies. Kiko Llaneras, over at elespanol.com, and Virgilio Gomez Rubio,at the University ofCastilla-La Mancha, have produced interesting forecasts for the 2015 Election. They have the larger merit, compared to our own effort, of having avoided the aggregation of “Other” parties into a single entity, as well as having produced forecasts for each single provincial race.
[In our model, we did have a province elements in that the long-term component of the structural forecast did depend on variables that were defined at that geographical level. But we didn’t formally model each individual province as a single race…]
I put our results and error together with theirs in the following tables for comparison. For consistency, and to allow for proper comparison, I stick to our labels (including the “Other” aggregate). It should be noted that the other guys were more rigorous, testing themselves also on whether each seat in the “Other” category went to the party they forecast within that category. Hence their reviews of the effort may be harsher. That said, since none of the “Other” parties have a chance at winning the election, this rating strategy is fair enough for our purposes.

As it clear from this table, Virgilio had the smallest error, whilst all forecasts have similar error shares. Where Virgilio does better than both us and Kiko is in the PSOE forecast, which he hits almost on the dot, whilst we underestimate it. Furthermore he’s more accurate on the “Others”, as is Kiko, suggesting that producing provincial forecasts could help reduce error on that front. Finally, whilst our model falls short of forecasting the true swing in favour of the PP, it also has the smallest error for the two new parties, Ciudadanos and Podemos.
[I think this is interesting too and probably due to the formal inclusion of some information in the priors for these two parties, for which no or very limited historical forecast is available.]
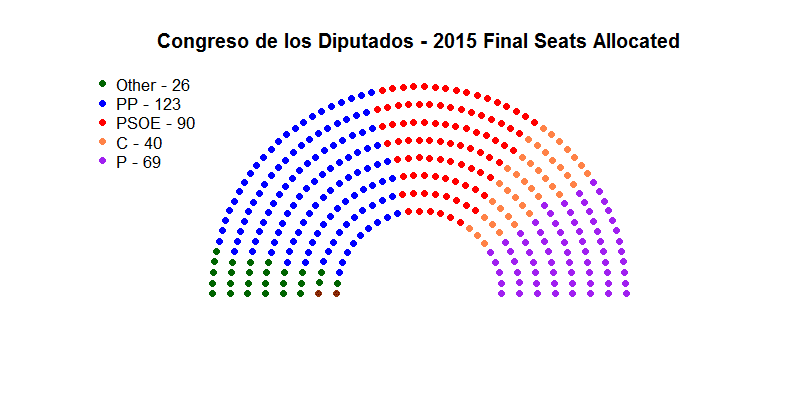
Looking at the actual results, we can only speculate as to the future of Spain. None of the parties even came close to touching the magic number of 176 seats, needed for an outright majority. However some interesting scenarios may unfold: the centre-right (C+PP) only manages to put together 163 seats; the left, on the other hand, could end up being able to form a governing coalition. PSOE, IU and Podemos can pool their seats together to get to 161 and if they manage to convince some of the “Other” left-leaning parties, they could get the 17 seats they need in order to govern.
However, this would certainly be an extremely fragile scenario, which would lead to serious contradictions within the coalition: how could Podemos forge a coalition with the PSOE over extremely serious disputes such as the Catalonian independence referendum? Rajoy’s hope is that he’ll be able to convince the POSE to form a “Gran Coalition” for the benefit of the nation; however, this scenario, whilst being the preferred from the markets worldwide, is unlikely as the PSOE “smells blood” and knows it can get rid of Rajoy, if it holds out long enough.
In conclusion, our model provided a very good direction for the election and predicted the main and most important outcome of the election: a hung parliament and consequent uncertainty. However, through a more thoughtful modeling of polls; an effort to disaggregate “Others” into its respective parties; and province-level forecasts, we could go a long way in reducing our error.