The Oracle (5. Or: Calibration calibration calibration…)
First off, a necessary disclaimer: I haven’t been able to write this post before a few of the games of the final round of the group stage have been played, but I have not watched the games so far and have run the model to predict round 3 _as if _none of the games had been played.
Second, we’ve been thinking about the model and whether we could improve it in light of its predictive ability proven so far. Basically, as I mentioned here, the “current form” variable may not be very well calibrated to start with \(-\) recall it’s based on an evidence synthesis of the odds against each of the teams, which is then updated given the observed results and weighting them by the predicted likelihood of each outcome occurring.
Now: the reasoning is that, often, to do well at competitions such as the World Cup, you don’t necessarily need to be the best team (although this certainly helps!) \(-\) you just need to be the best in that month or so. This goes, it seems to me, over and above the level and impact of “current form”.
To make a clearer example, consider Costa Rica (arguably the dark horses of the tournament, so far): the observed results (two wins against relatively highly rated Uruguay and Italy) have improved their “strength”, by nearly doubling it in comparison to the initial value (based on the evidence synthesis of a set of published odds). However, before any game was played, they were considered the weakest team among the 32 participating nations. Thus, even after two big wins (and we’ve accounted for the fact that these have been big wins!), their “current form/strength” score is still only 0.08 (on a scale from 0 to 1).
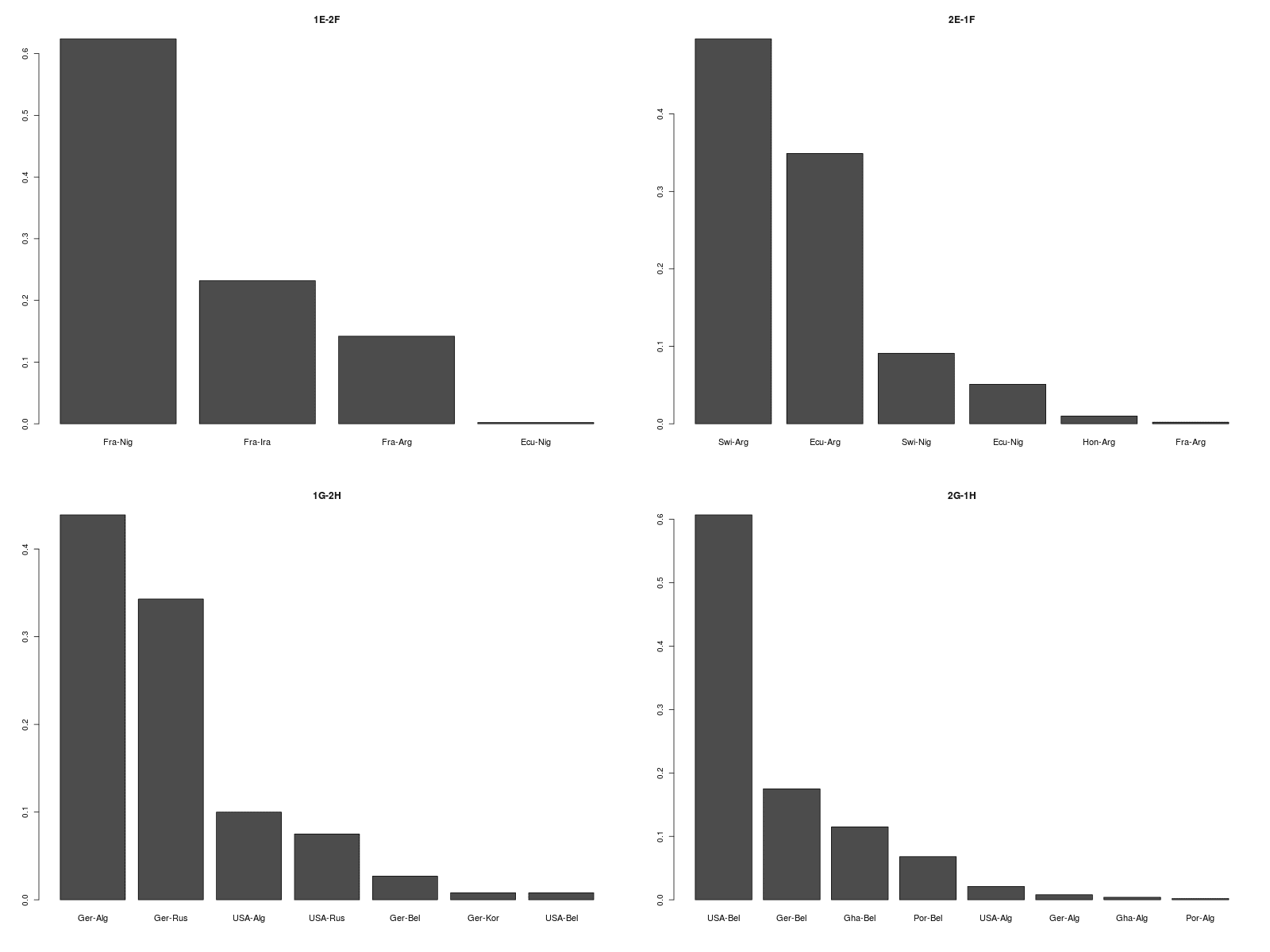
Consequently, by just re-running the model including all the results from round 2 and the updated values for the “current form” variable, the prediction for their final game is a relatively easy win for their opponent, England, who on the other hand have had a disappointing campaign and have already been eliminated. The plots below show the prediction of the outcomes of the remaining 16 games, according to our “baseline” model.

So we thought of a way to potentially correct for this idiosyncrasy of the model [Now: if this were serious work (well \(-\) it is serious, but it is also a bit of fun!) I wouldn’t necessarily do this in all circumstances (although I believe what I’m about to say makes some sense)].
Basically, the idea is that because it is based on the full dataset (which sort of accounts for “long-term” effects), the “current form” variable describes the increase (decrease) in the overall propensity to score of team A when playing team B. But at the World Cup, there are also some additional “short-term” effects (eg the combination of luck, confidence, good form, etc) that the teams experience just in that month.
We’ve included these in the form of an offset, which we first compute (I’ll describe how in a second) and then add to the estimated linear predictor. This, in turn, should make the simulation of the scores for the next games more in line with the observed results \(-\) thus making for better prediction (and avoiding not-too-realistic prediction).
The computation of the offset is like so: first, we compute the difference between the expected number of points accrued so far by each of the team and the observed value. Then, we’ve labelled each team as doing “Much better”, “Better”, “As expected”, “Worse” or “Much worse” than expected, according to the magnitude of the difference between observed and expected.
Since each team have played 2 games so far, we’ve applied this rule:
- Teams with a difference of more than 4 points between observed and expected are considered to do “much better” (MB) than expected;
- Teams with a difference of 3 or 2 points between observed and expected are considered to do “better” (B) than expected;
- Teams with a difference between -1 and 1 point between observed and expected are considered to do just “as expected” (AE);
- Teams with a difference of -2 or -3 points between observed and expected are considered to do “worse” (W) than expected;
- Teams with a difference of more than -4 points between observed and expected are considered to do “much worse” (MW) than expected.
Roughly speaking this means that if you’re exceeding expectation by more than 66% then we consider this to be outstanding, while if you’re difference with the expectation is within \(\pm\) 20%, then you’re effectively doing as expected. Of course, this is an arbitrary categorisation \(-\) but I think it is sort of reasonable.
Then, the offset is computed using some informative distributions. We used Normal distributions based on average inflations (deflations) of 1.5, 1.2, 1, 0.8 and 0.5, respectively for MB, B, AE, W and MW performances. We choose the standard deviations for these distributions so that for teams performing “much better” than expected the chance of an offset greater than 1 on the natural scale (meaning an increase in the performance predicted by the “baseline” model) would be approximately 1 (for MB), .9 (for B), .5 (for AE), .1 (for W) and 0 (for MW). The following picture shows this graphically.

Including the offsets computed in this way produces the results below.

The Costa Rica-England game is now much tighter \(-\) England are still predicted to have a higher chance of winning it, but the joint posterior predictive distribution of the goals scored looks quite symmetrical, indicating how close the game is predicted to be.

So, based on the results of the model including the offset, these are our predictions for the round of 16.