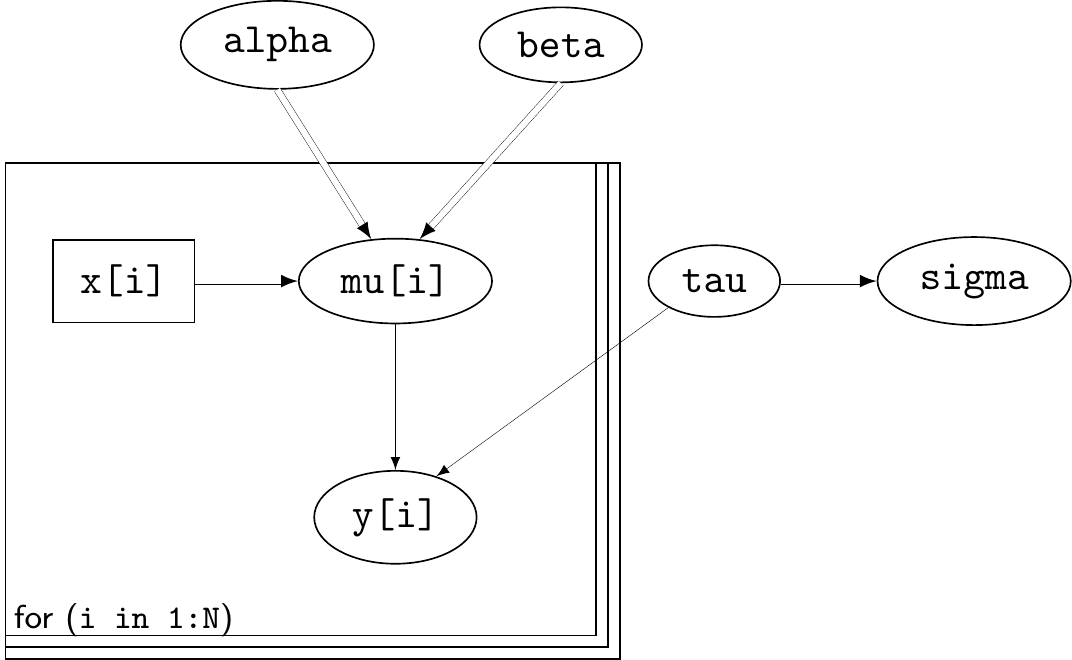
model {for (i in1:N) { y[i] ~dnorm(mu[i], tau) mu[i] <- alpha + beta*x[i] } tau ~dgamma(0.1,0.1) sigma <-pow(tau,-0.5) alpha ~dnorm(0,0.01) beta ~dnorm(0,0.01)}
BUGS/JAGS have a built-in parser, which inspects the set of declarations and translates them into a DAG
Exploits as much as possible the underlying conditional independence relationships to speed up computation
Example — drug
Consider a drug to be given for relief of chronic pain
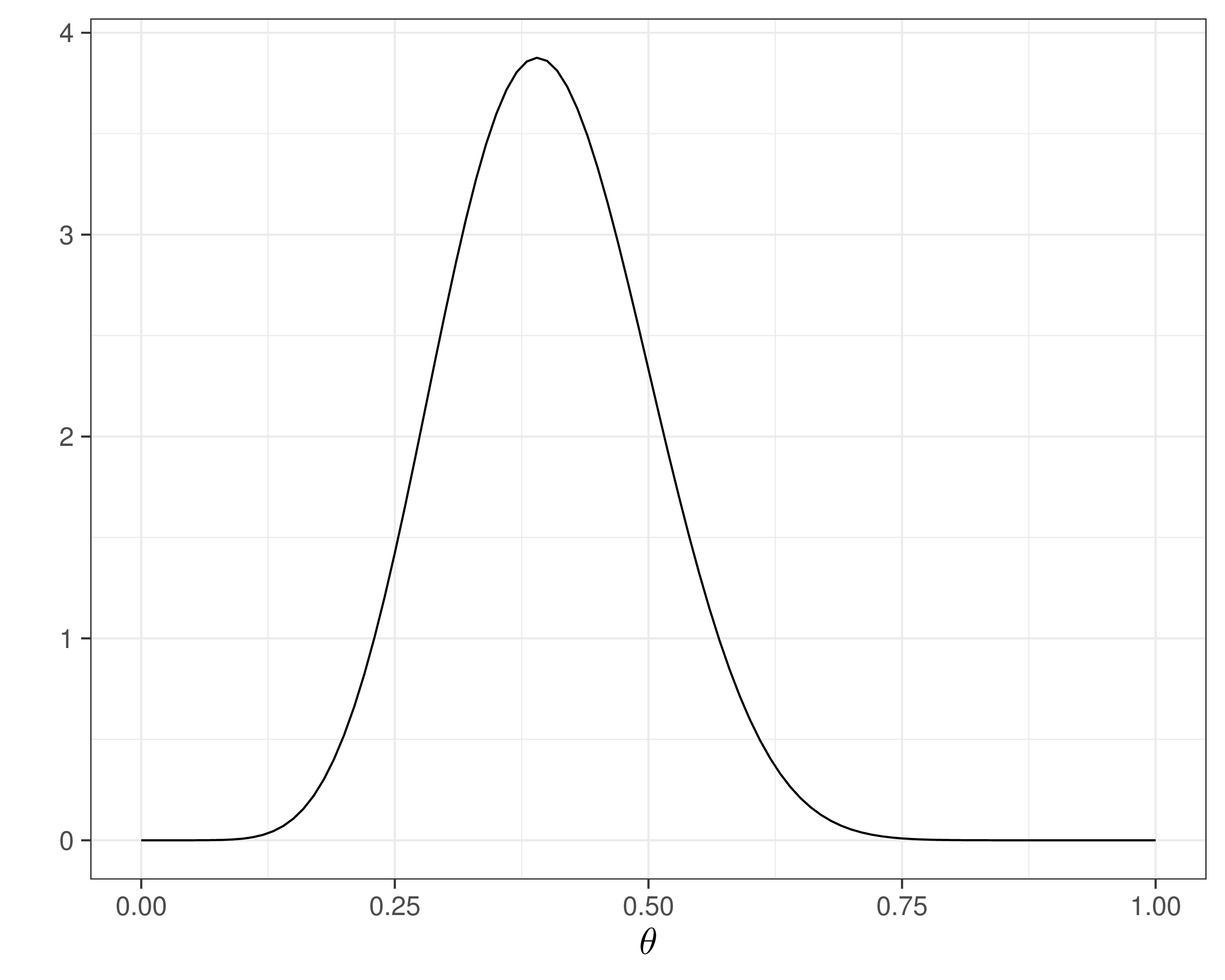
Experience with similar compounds has suggested that annual response rates between 0.2 and 0.6 could be feasible
Interpret this as a distribution with mean = 0.4 and standard deviation = 0.1
Can encode these into a Beta(9.2, 13.8) prior
Example — drug
Suppose we can actually run a small pilot study, in which we observe \(y=15\) in \(n=20\) individuals to whom we give the drug and who are relieved from the back pain
Update uncertainty over \(\theta\) = probability of “success” for the drug
Predict number of successes in the next \(m=40\) patients
NB: \(p(y_{pred}\mid y)\) is the predictive distribution
Mixes up (revised/posterior) uncertainty in \(\theta\) and sampling variability (Binomial model)
Running JAGS from R
Map the “pen-and-paper” model into JAGS code
Can code up the model in a .txt. file
model { theta ~dbeta(a,b) y ~dbin(theta,n) y.pred ~dbin(theta,m)}
… OR write directly in R as a function
model.code=function(){ theta ~dbeta(a,b) y ~dbin(theta,n) y.pred ~dbin(theta,m)}
In R, provide the observed data
data=list(a=9.2, b=13.8,y=15,n=20,m=40)
Use JAGS to obtain the posterior and the predictive distributions
# Loads the relevant R package to interface with JAGSlibrary(R2jags)# Runs the modelm=jags(data=data,parameters.to.save=c("y.pred","theta"),inits=NULL,model.file=model.code,n.chains=2,n.iter=6000,n.burnin=1000,n.thin=1)
Running JAGS from R
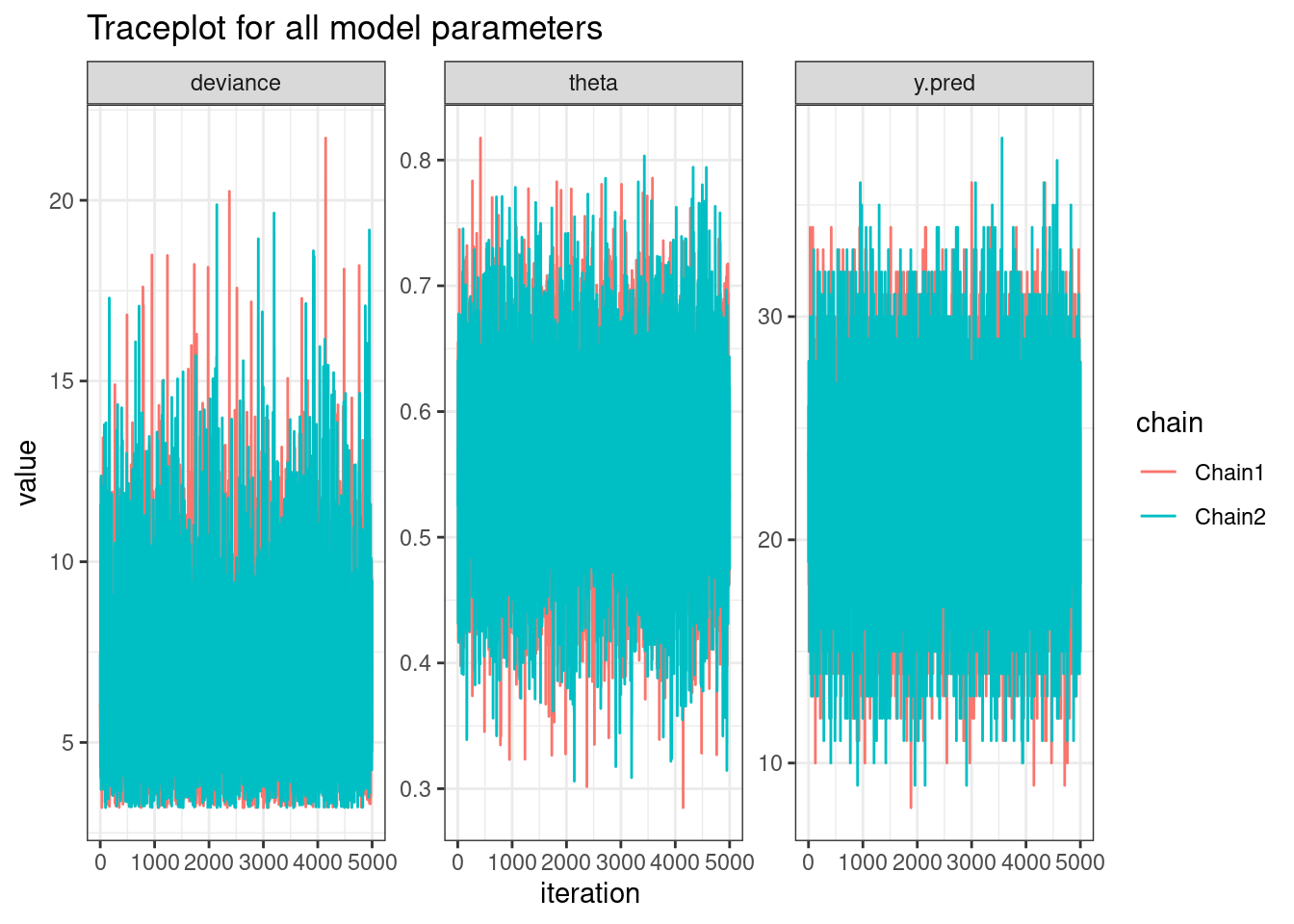
The object m contains the MCMC output
# Shows the names of the elements inside the object 'm'm |>names()
Inference for Bugs model at "/tmp/RtmpGy2l2J/model22c593971f56c.txt",
2 chains, each with 6000 iterations (first 1000 discarded)
n.sims = 10000 iterations saved. Running time = 0.015 secs
mu.vect sd.vect 2.5% 97.5% Rhat n.eff
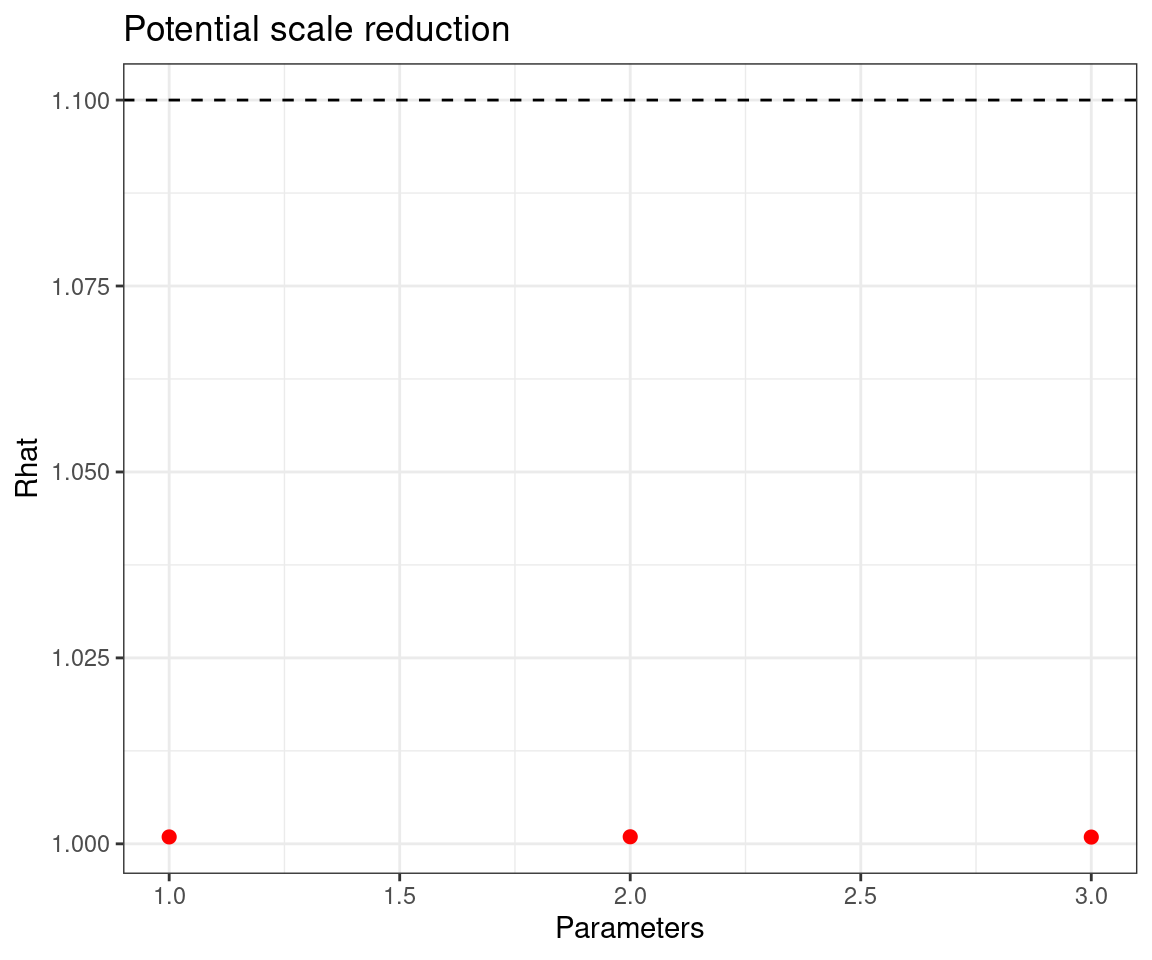
theta 0.563 0.076 0.411 0.708 1.001 10000
y.pred 22.491 4.352 14.000 31.000 1.001 10000
deviance 6.660 2.444 3.372 12.683 1.001 10000
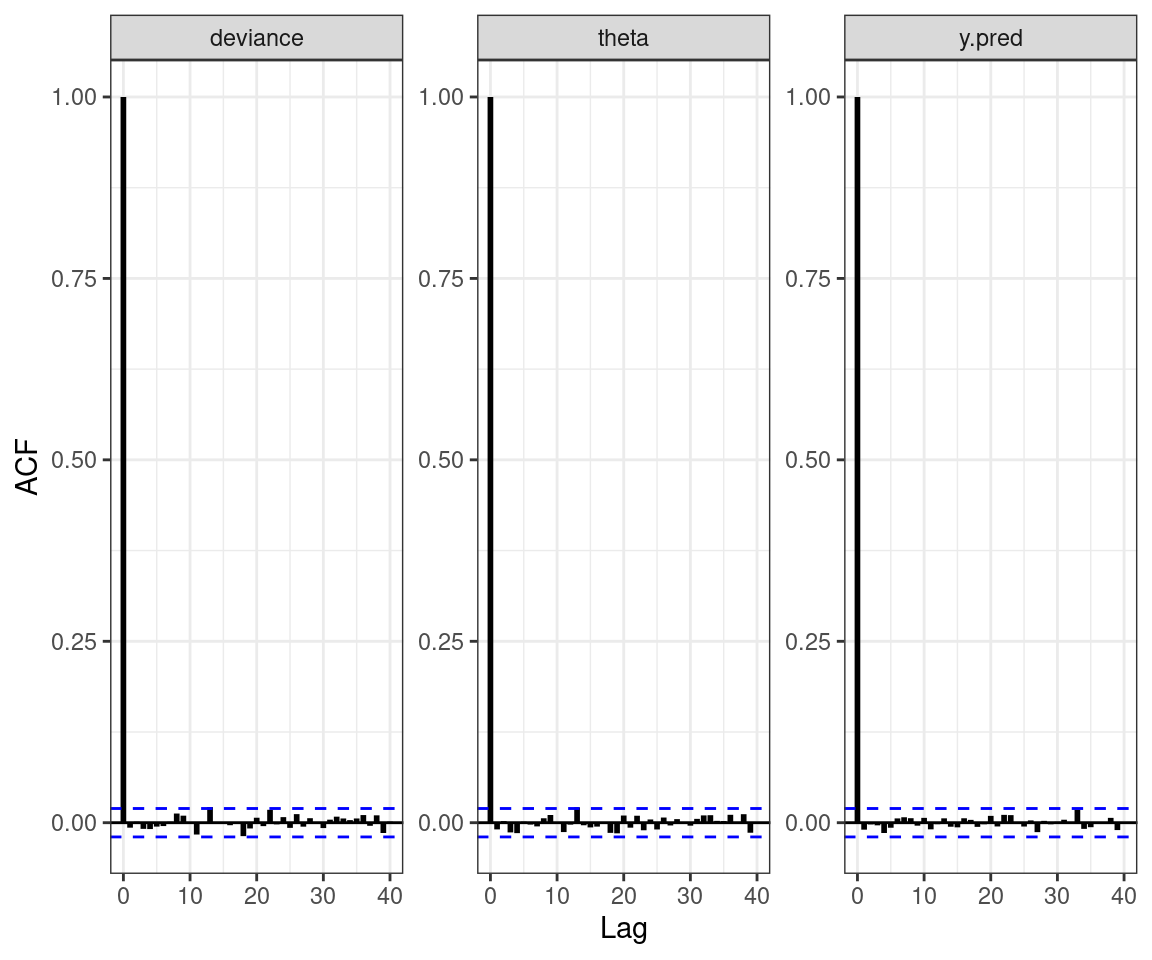
For each parameter, n.eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor (at convergence, Rhat=1).
DIC info (using the rule: pV = var(deviance)/2)
pV = 3.0 and DIC = 9.6
DIC is an estimate of expected predictive error (lower deviance is better).
Post-processing the JAGS output
We can use directly R code to post-process the results
Or use standardised packages
bmhe (for diagnostics & plots)
BCEA (for economic evaluation)
…
# Installs relevant packages# Directly from CRAN (main repository)install.packages("BCEA")install.packages("R2jags")# Or from GitHub (more experimental packages)remotes::install_github("giabaio/bmhe_utils")remotes::install_github("giabaio/R2jags")